요새 모델들은 단순한 이미지의 인식 뿐만이아닌 생성을 해내고 이것의 끝판왕은 natural anguage description 으로부터 이미지를 생성하는 작업이다
새나 꽃같은 제한된 도메인에서 놀라운 결과가 나오지만, 많은 오브젝트와 많은 관계를 가진 이미지는 생성이 어렵다
이 한계를 극복하려고 오브젝트와 관계를 명시적으로 추론 할수 있는 Scene graph에서 이미지를 생성하는것을 제안했다
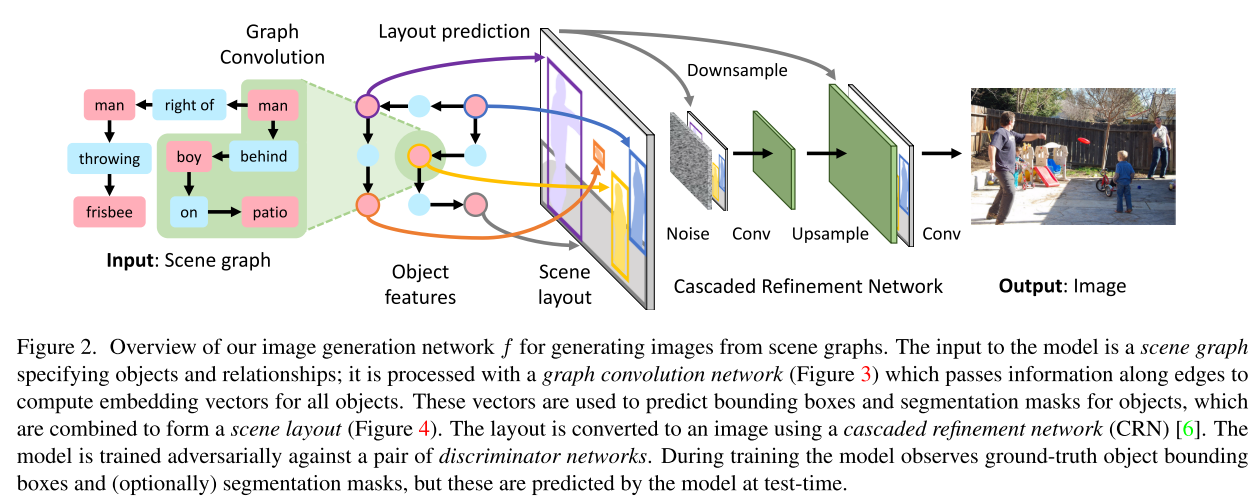
GCN을 사용하여 Graph를 입력받고 예측된 박스와 Segmentation 마스크로 Scene layout을 계산하고 이것을 기반으로 이미지로 생성하고 한쌍의 discriminator의 통해 적대적으로 학습되는 연속적인 네트워크다
2. Related Work
현재 이미지 생성모델 크게 3가지로 분류된다
GAN, VAE, Autoregressive approaches
Conditional Image Synthesis
conditional 한 생성은 추가적인 입력을 Generator와 Discriminator양쪽에 넣거나 Discriminator에만 label을 넣기도 하는데 우리는 후자를 사용한다
기존연구에서 text를 GAN을사용하여 이미지를 생성하거나 그것을 발전시켜 multistage 생성을 하게한 연구도있음
우리연구와 관련 깊은 연구에는 sentence와 keypoint 양쪽을 사용하여 contidional 한 생성을 하거나, 그리고 생성외에도 관측되지 않은 중요한 키포인트를 예측하는 방식도 있다
Chen and Koltun 은 Sementic Segmentation을 기반으로 percepual feature reconstruction loss와 Cascaded refinement network 를 사용 하여 고해상도 거리 이미지를 생성하였다
이 CRN 구조를 채용 함
Scene Graph
Scene Graph란 노드는 오브젝트를, 엣지는 관계를 표현하는 방향성 그래프로 이미지 검색이나 캡셔닝에 주로 활용되어 왔다
문장을 씬그래프로 변환하거나 이미지에서 씬그래프를 예측하는 연구들도 있다
대부분 연구에서 사람이 만든 주석이 달린 Visual Genome datasets을 사용한다
Deep Learning on Graphs
어떤 고정된 그래프에서 노드를 임베딩 하는 방법들이 있으나 우린 그것과 다르게 각 Forword마다 다른 그래프를 처리해야한다
GCN은 우리가 원하는 방향과 비슷하게 임의의 그래프에서 작동한다
molecular property prediction, program verification, modeling human motion 등에서 사용되고 spectral domain을 활용한 기법들도있으나 우린 사용안함
3. Method
우리 목표는 오브젝트와 관계를 설명하는 Scene graph를 입력하여 그 그래프와 관련된 Realistic한 이미지를 생성하는것인데 여기엔 세가지 과제가 존재한다
첫째로 그래프 구조의 입력을 위한 처리방법이고
두번째는 생성된 이미지가 얼마나 그래프를 잘 설명하는지 확인해야하고
세번째는 생성된 이미지가 얼마나 사실적인지 확인해야한다
전체적인 구조
$\hat{I} = f(G,z)$
그래프에서 이미지를 생성하는 네트워크$f$ (CRN)
생성된 이미지 $I$, Scene Graph $G$
$G$는 GCN에 의해 오브젝트마다 임베딩이 되는데 이과정에서 엣지 정보가 섞인다
GCN에서 나온 object embedding vector를 사용해 각 object의 박스와 segmentation mask를 예측하고 이것을 합쳐 Scene layout을 구성, 그리고 CRN을 통해 최종적으로 이미지를 생성
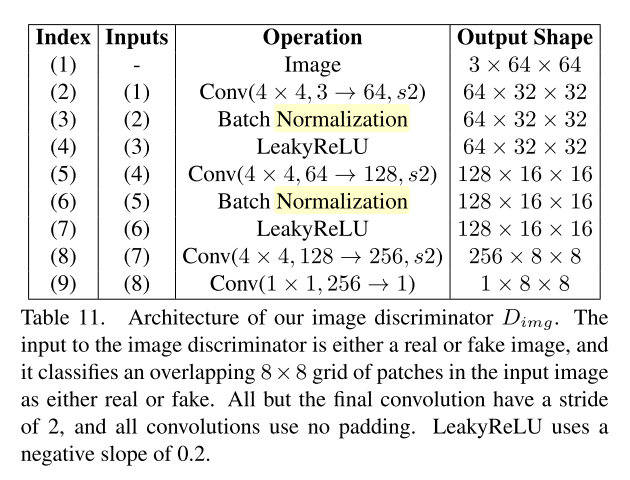
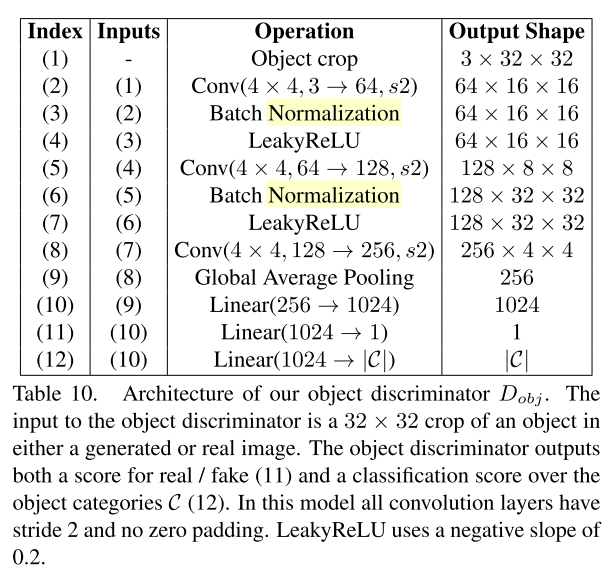
한쌍의 Discriminator $D_{img}, D_{obj}$를 통해 적대적학습을 하여 현실적인 그림인지와, 현실적인 오브젝트를 담고있는지를 판단하게 함
Scene Graph 의 구조
기본적으로 $(O,E)$
$O = {o_1, o_2,…,o_n}$ : object ($o_i \in C$)
$E \in O \times R \times O$
$(o_i, r, o_j)$ 의 형태를 가짐 ($r \in R$)
사전 학습된 Embedding Layer를 사용해 각 노드와 엣지를 $D_{in}$의 shape를 가진 dense vector로 변환 시킴(NLP에서의 Embedding과 비슷)
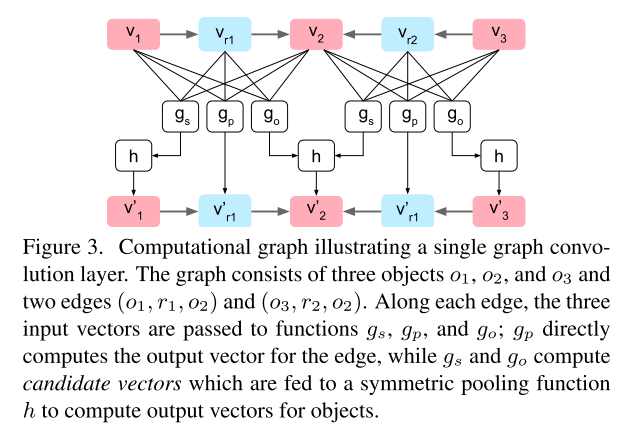
Graph Convolution Network (일반적인 GCN과 매우다름)
$(v_i, v_r) \in D_{in}$ : 입력 shape, $(v_i’, v_r’) \in D_{out}$ : 출력 shape
$(v_i, v_r, v_j)$ : 실제 입력되는 형상
$g_s, g_p, g_o$ 모든 입력에 대해 3개의 함수를 사용
$g_p$ : Predicate (엣지 벡터 변환)
$g_s$ : Subject
$g_o$ : Object
$v_r’ = g_p(v_i, v_r, v_j)$
출력 엣지를 구함 (연산이 매우 간단)
$v_r’ = h(V_i^s \cup V_i^o)$
$V_i^s = {g_s(v_i,v_r,v_j) : (o_i,r,o_j) \in E }$
$V_i^o = {g_o(v_j,v_r,v_o) : (o_j,r,o_i) \in E }$
해당 오브젝트가 subject에 사용된 관계는 $g_s$, object로 사용된 관계는 $g_o$를 사용하여 연결
$h$ 함수는 간단히 각 벡터의 위치별평균을 사용 후 FCL 두개 통과
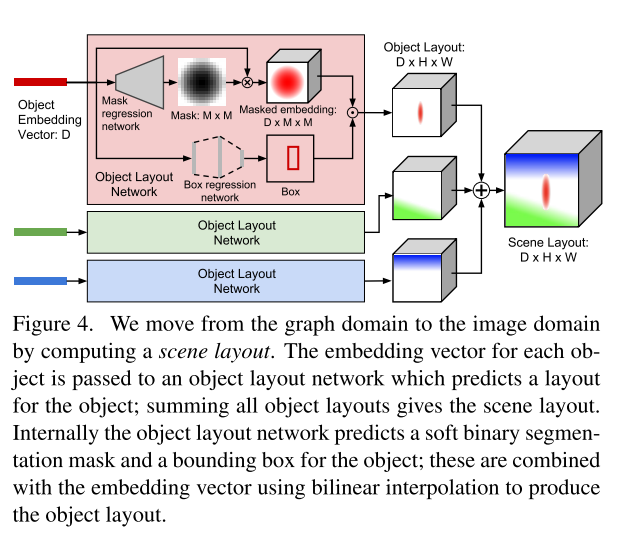
Scene Layout
GRAPH를 이미지로 만들기 위해서는 이미지 도메인으로의 변환이 필요
Object Layout Network
2D 에서의 대략적인 Layout을 생성하기 위한 네트워크
Box Regrresion Network
이미지의 위치를 박스로 나타낼 네트워크로 object embedding 정보를 사용해 꼭지점의 위치를 예측
$(x_0,y_0,x_1,y_1)$, [0,1]로 Normalize된 상태로 좌상우하 위치
Mask Regression network
생성된 마스크 $(1 \times M \times M)$ 을 embedding$(D)$ 에 곱해 $(D \times M \times M)$ 의 텐서를 생성 후 BoxRegression 정보와 결합하여 $(D \times H \times W)$ 의 최종 Scene Layout 생성
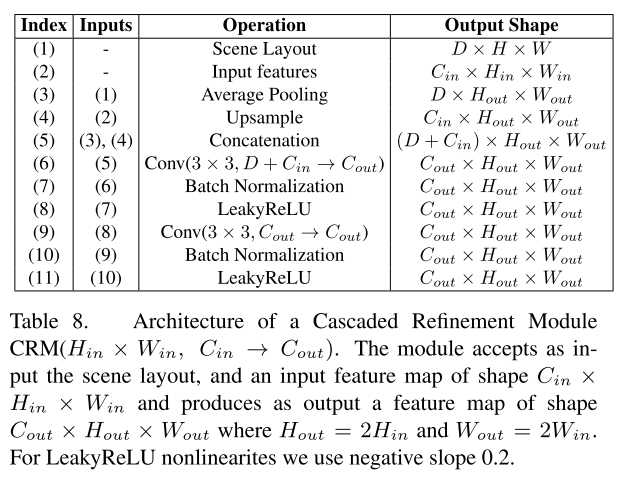
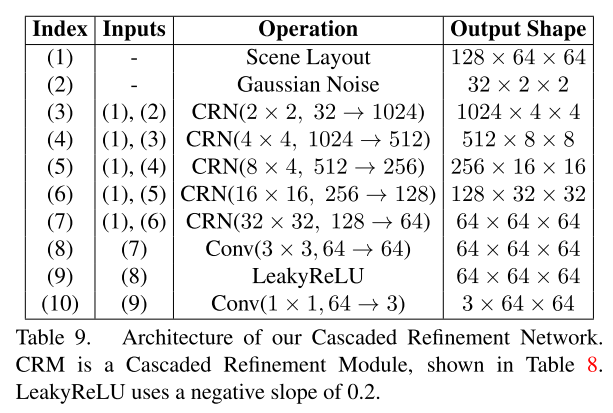
Cascaded Refinement network (Generator)
앞에서 생성된 Scene Layout에 의존한 의미지를 생성해야하는데 이것을 위해 CRN을 사용
각 모듈마다 해상도가 두배씩 점차적으로 증가시키며 Scene Layout 정보(down sampling)와 이전 모듈에서의 출력을 concatenate 해서 사용