GAN을 학습할때 데이터가 너무 적을경우 Discriminator가 overfitting되어 훈련이 잘 안됨
이런 제한된 데이터에서의 훈련에 안정성을 현저히 높여주는 Adaptive discriminator augmentation mechanism 을 제안
모델의 구조 혹은 Loss를 변경하지않고 from scratch 와 fine-tuning 모두 적용 가능
수천단위의 데이터만으로 좋은 결과를 냄
새로운 GAN의 domain을 열었다고 생각함
1. Introduction
최근 GAN 모델들은 성능은 좋았지만 대부분 온라인을 이용한 매우 많은 이미지를 사용하여 학습하였음
하지만 라벨링이 필요업다 해도 이런 큰 데이터를 만든는것은 여전히 어려움
특히 완전히 새로운 데이터에 적용 할 경우 $10^5 \sim 10^6$ 개의 데이터를 생성해야함
덕분에 의학쪽에서 잘 이용이 되지 못하고 있다고 함
만약 필요 이미지의 수를 줄인다면 다양한 응용프로그램에 도움이 될 수 있을 것
핵심적인 문제는 Discriminator가 학습데이터에 overfit 되는것
Discriminator가 의미없는 정보만 주게되어 학습이 발산해버림
이미지 분류에서 Data Augmentation 은 이것을 해결하는 표준 솔루션으로 사용됨
하지만 Generator의 경우 이것이 Augmentation에 대한 분포를 학습할 수 있음
예를 들면 노이즈가 추가될 경우 원래 데이터엔 없던 노이즈도 생성함
여기서 leak이라는 용어가 사용되는데 augmentation 된 정보가 Generator에 흘러가는 것을 뜻함
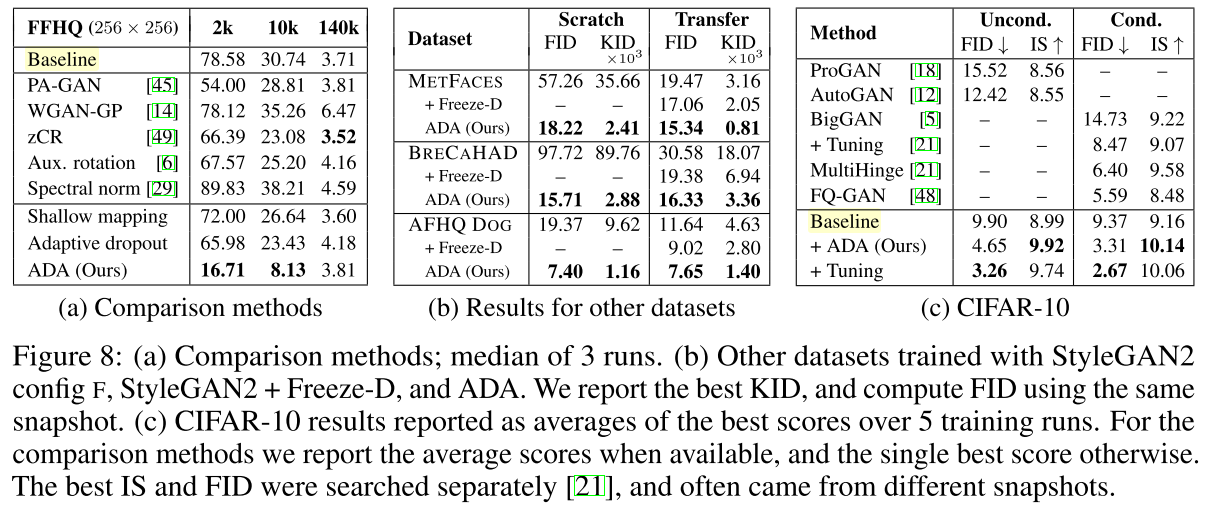
Discriminator가 overfit 되지 않는 새로운 augmentation방식을 적용
leak을 방지하기 위해 이것이 발생하는 조건을 분석
최종적으로 데이터와 훈련설정에 의존하지 않는 General 한 방식을 설계
2. Overfitting in GANs
데이터의 양이 GAN 에 미치는 영향 연구
설정
FFHQ 및 LSUN CAT 데이터에서 샘플링
광범위한 Hyperparameter 설정을 위해 다운샘플링한 $256 \times 256$ 버전을 사용
생성된 50k 개의 이미지와 모든 실제 이미지 사이의 FID를 기준으로 평가
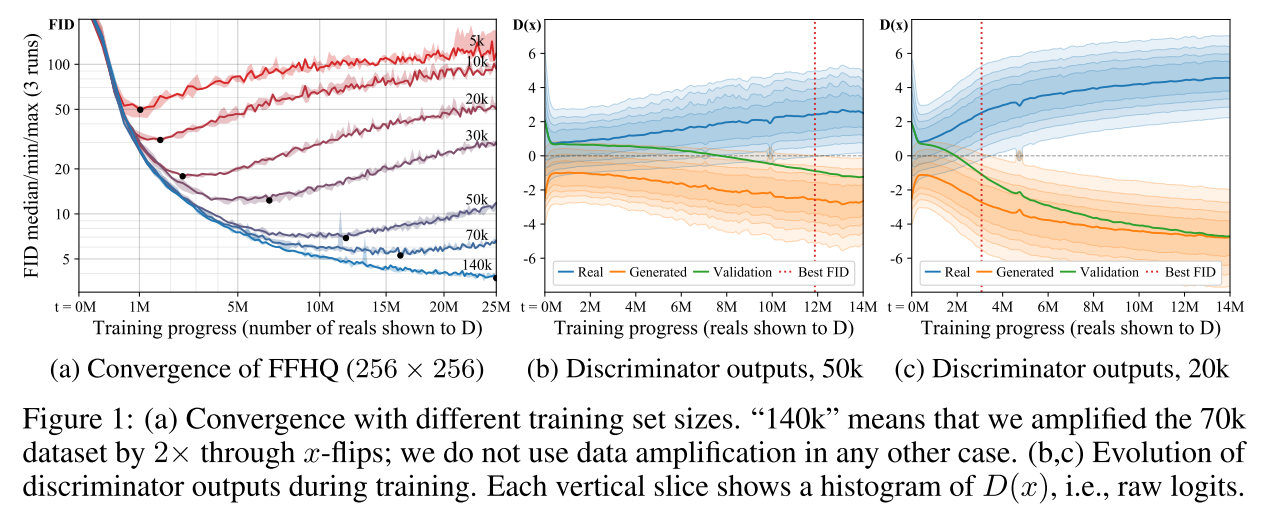
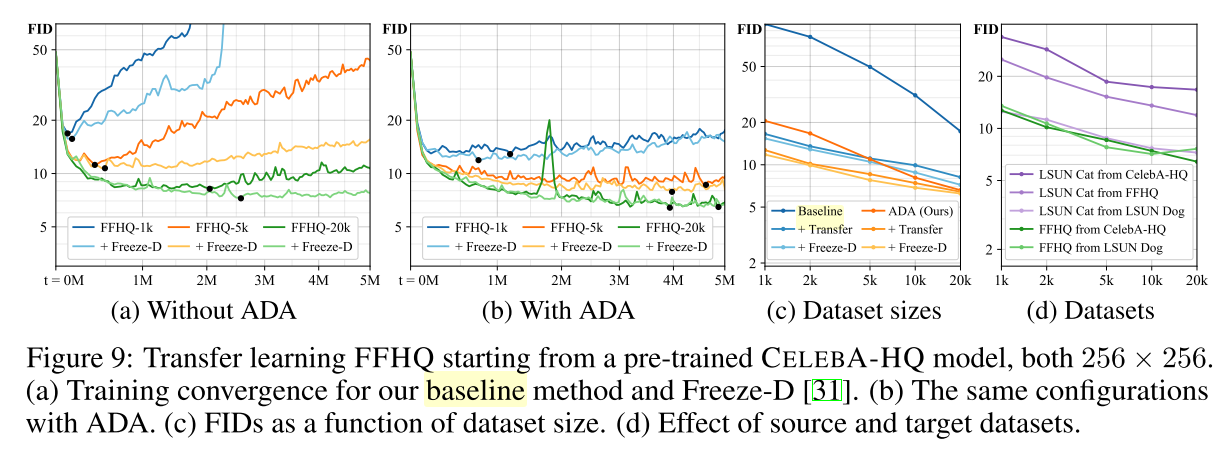
결과(FFHQ)
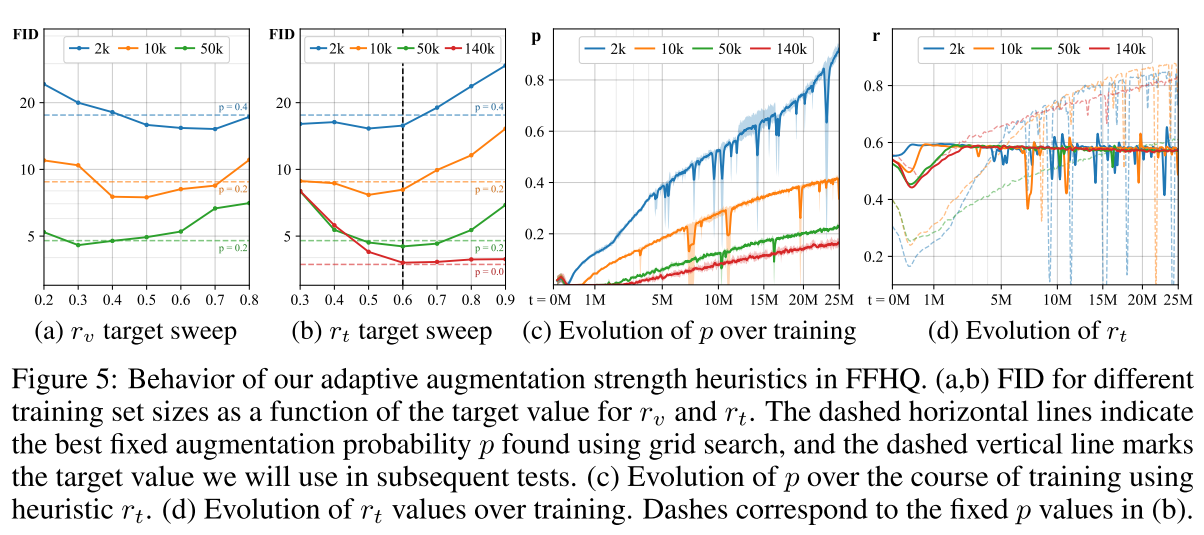
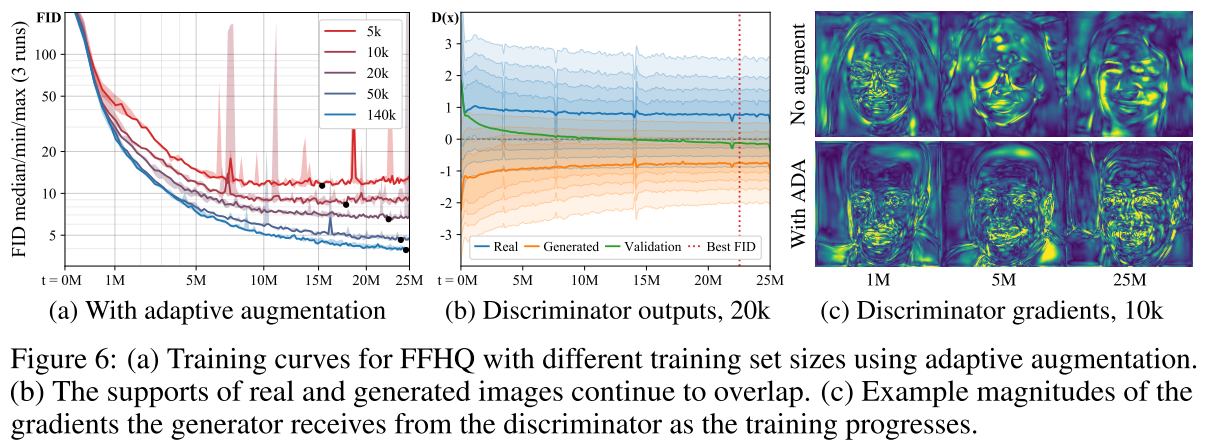
여러가지 설정에서 특정구간 이후 전부 FID가 오르는것을 보임
오른쪽 b,c 를보면 처음엔 어느정도 겹치지만 Discriminator가 과적합되면서 완전히 분리됨
특히 Validation이 생성된 이미지쪽으로 완전히 치우는것을 보임 (완벽한 과적합의 신호)
이것을 해결하는 augmnetation 방식을 설계하는것이 목표
2.1 Stochastic Discriminator Augmentation
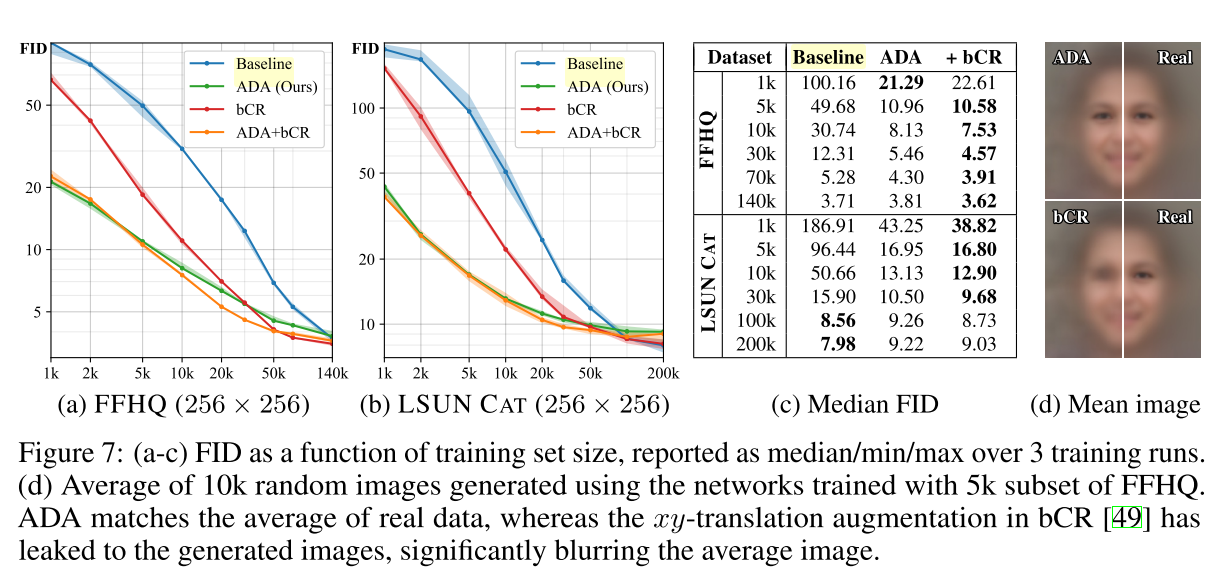
balanced consistency regularization (bCR)
Discriminator 학습시 동일한 증강을 부여하고 동일한 출력이 나오게 하는 방식 (CR손실 추가)
Generator 학습시엔 panalty가 적용되지 않아 자유롭게 생성 가능해 leak이 발생해 그냥 augmentation을 사용하는것과 유사한 결과가 나옴
Discriminator augmentations (DA)
기본적으로 방식은 유사하나 새로운 손실항을 추가하지않고 Generator를 학습할때도 augmentation을 수행
간단하지만 현재까지 주목받지 못한 방법이라함
하지만 구조가 직관적으로 봐도 매우 불안정 할수밖에 없기에 이것이 잘 될거라 생각 자체를 못했을거라 말함
leak이 발생하는 조건을 모두 찾은 후 완전한 구조를 구축
2.2 designing augmentations that do not leak
DA 방식의 문제
DA 방식은 왜곡시킨 제품을 보여주고 원래 제품을 가져와라 라고 하는 것
AmbientGAN: Generative models from lossy measurements(Bora et al.) 에서는 corruption 과정이 invertible transformation 이라면 훈련이 암묵적으로 왜곡을 해결하고 원래의 분포를 찾는다는것을 발견
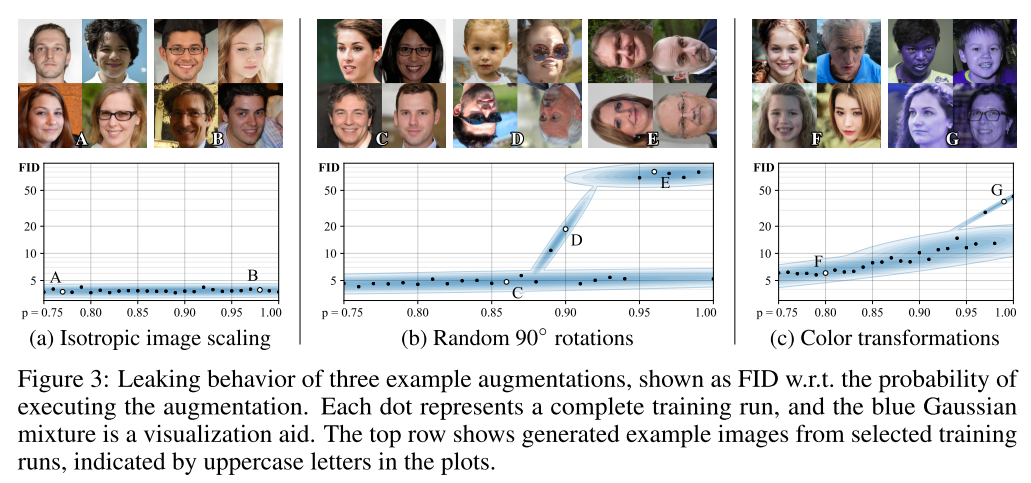
우리는 이런 augmentation 기법을 non-leaking 이라 부르고 이 기법들은 적용된 데이터만으로 기존 데이터와의 일치여부르 구분 할 수 있는 능력을 가짐
이미지픽셀을 90프로확률로 0으로 만드는것은 invertible 함, 사람도 10프로의 이미지만으로도 90프로의 검은부분을 무시하고 추론할 수 있다
하지만 90도 단위 랜덤 회전변환의 경우 실제이미지의 위치가 어디였는지 알수없기에 원복이 불가능하지만 확률 이 1보다 작아진 다면 올바른 형태의 확률이 높아지기에 원래 모양을 예측할 수있음
여러가지 augmentation이 확률이 1미만인 조건에서 non-leaking 해질 수 있음
고정된 순서로 non-leaking 증강을 구성하면 전체적인 non-leaking 이 가능해짐
Isotropic image scaling 의 경우 확률에 상관없이 결과가 균일 (non-leaking)
하지만 Random Rotation의 경우 확률이 높으면 generator는 랜덤한 하나를 선택하게됨 (확률이 1일때만 발생하는것은 아님)
이 확률이 낮아질수록 처음엔 잘못 선택하더라도 높은 확률로 올바른 분포를 찾아감
Color transformations 도 0.8이전엔 균일한 분포를 보임
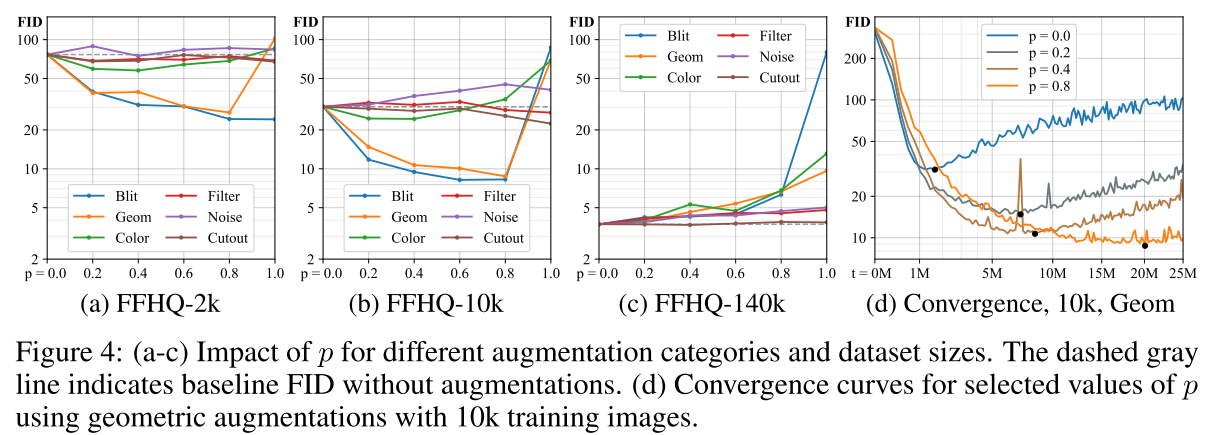
2.3 Out augmentation pipeline
RandAugment 에서 봤듯이 다양한 augmentation을 적용하는 것이 좋다는 가정에서 시작