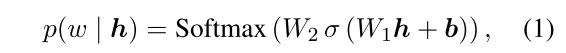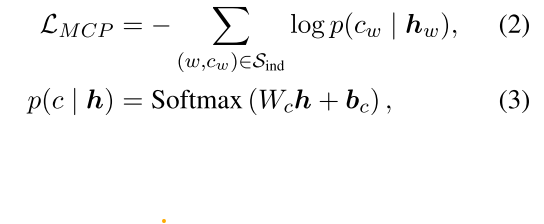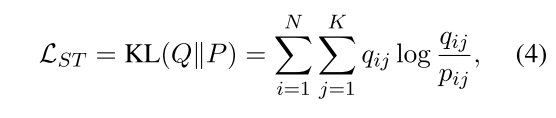카테고리를 의미하는 단어를 찾고 해당 단어를 masking하고 category를 예측하는 모델을 훈련
self training을 통해 모델을 일반화
학습에 label을 사용하지 않고 4개의 데이터셋에 대해 약 90%의 정확도를 달성
2. Related Work
Semi-Supervised and Zero-Shot Text Classification
Semi-Supervised 방식은 크게 두가지 구조가 주로 사용된다
Augmentation-based
augmentation 된 객체를 사용하고 입력에 대해 예측력이 낮아지지 않도록 정규화를 시행하는 방식
Graph Based
단어를 기반으로 text network를 생성하고 문서나 label에 대한 임베딩 혹은 GNN을 사용해 학습
Zero-shot
사전 학습된 모델을 사용해 새로운 레이블에 적용하는 방식
레이블링된 문서가 없는경우 사용할 수 없음 (?????)
Weakly-Supervised Text Classification
이 방식은 label의 단어수준 설명에만 의존하여 문서를 분류하여 label이 없어도 사용할수 있는것을 목표로 함
초창기에는 Wiki같은 거리가 먼 label에 의존해 label이름의 의미 해석과 문서와의 관련성을 학습시킴(dataless 방식)
Topic 모델은 seed 기반 분류에 사용되는데 Dirichlet 사전분포을 사용해 문서의 사후분포를 추정한다는데 모르겠네요???
최근엔 이것을 위한 신경망이 개발되었는데 pseudo 문서를 생성하여 label을 나타내는 단어를 탐지해서 생성한 pseudo labeling을 사용하여 훈련시키는 방식을 사용한다
이 방식은 scratch부터 훈련해야하고 dataless한 방식에 적용되지 못한다
이 논문에선 label의 이름의 의미를 이해하는것과 feature representation learning에 강해지기 위해 사전 훈련된 LM을 사용한다
3. Method
LOTClass : Label-Name-Only Text Classification
BERT 를 기반으로 한 모델을 사용하였으나 다른 모델에도 쉽게 적용가능
Category Understanding via label name Replacement
사람은 label의 이름만 들어도 이해를 할수 있음
사전학습된 모델을 사용해 레이블 이름에서 category vocabulary를 배우는 방법을 고안
교환이 가능한 단어는 의미가 비슷할것이다 라는 가설 설정
Corpus에서 Label 이름이 발생할때마다 BERT encoder를 사용하여 전체 문장 V를 입력해 해당 위치에 임베딩된 벡터 $h$를 구하고 MLM모델에 입력하여 모든 단어에 대해 출현할 확률을 계산
$W_1, W_2, b$ 는 pre-trained된 MLM
단어 출현확률을 내림차순으로 정렬하여 50개를 대체 유효한 단어로 설정
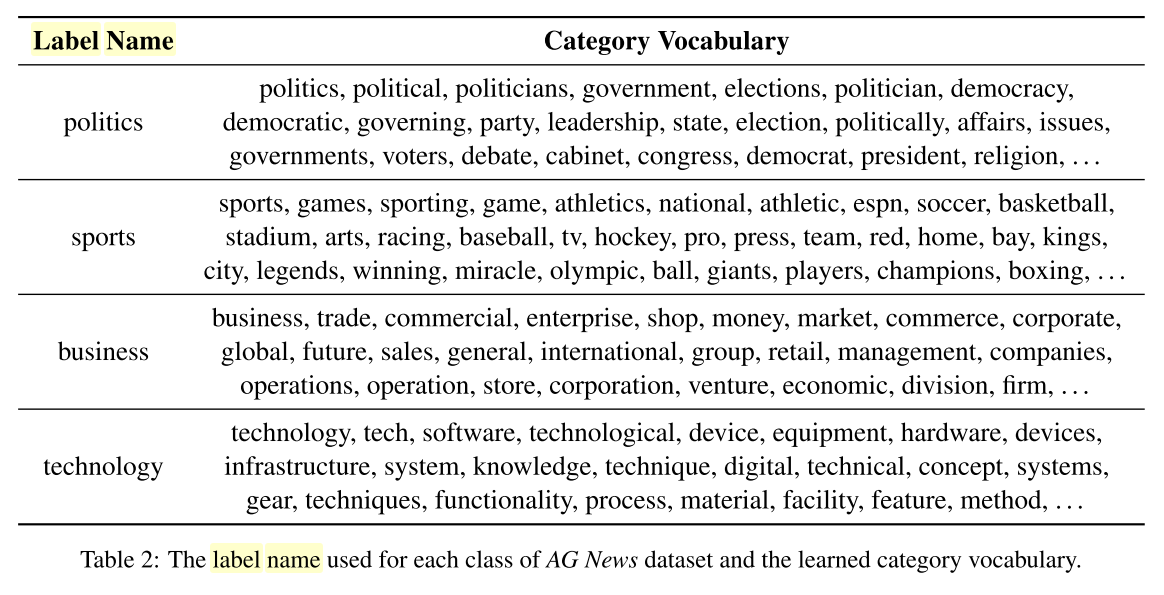
모든 문서에 대해 각 클래스별로 많이 대체한 순으로 100개의 워드를 선정하여 category vocaburaly로 사용
stopword나 여러 카테고리에 중복으로 등장한 단어는 제거함
Masked Category Prediction
모델이 category를 표현하는 단어(category-indicative word)에 초점을 맞추는 것을 원함
직접적인 방법으로는 모든 category vocabulary에 직접 표현하는것 이나 문제가 있음
단어의 의미는 문맥화 되어있기에 이 키워드가 반드시 범주를 나타내는것은 아님
category vocabulary의 범위가 제한적이라 유사한 의미를 가져도 포함 안될 수 있음
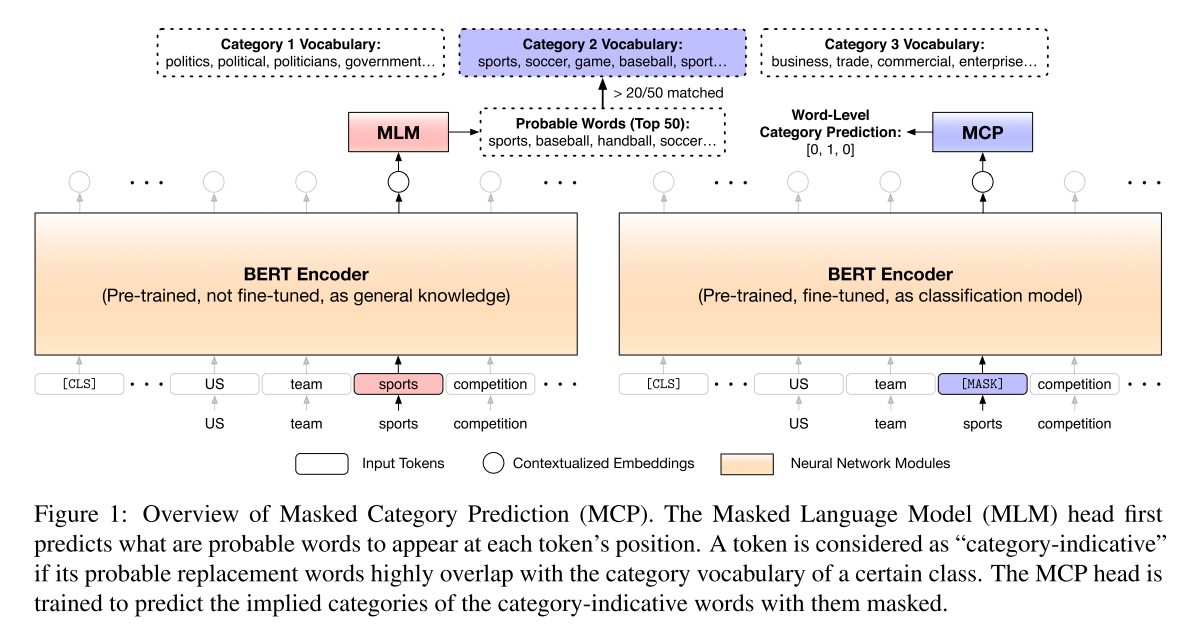
이 방식을 해결하기 위해 Masked Category Prediction 이라는 task 추가
단어가 masked 단어의 암시적인 category를 예측하기 위해 supervised 학습을 하는것이 목표
앞절에서 사용한 방식과 비슷하게 대체 단어들의 contextualized meaning을 파악
50개의 대체가능 단어를 찾고 이중 20개 이상이 category vocaburaly에 포함된다면 이것을 category-indicative word 로 지정하고 이 label 과함께 단어기반 supervision 이 가능한 데이터셋이 생김($S_{ind}$)
이후 각 category-indicative word $w$ 에 대해 이것을 [MASK]로 바꾸고 모델을 통과하여 contextualized embedding $h$를 구한 뒤 이것을 FCL을 통과시켜 softmax를 사용해 범주를 예측하게 학습함 (fine-tuning)
이 범주를 예측하기 위한 단어를 가려내는것은 단순히 키워드 암기 대신 word’s context 기반으로 범주를 예측하게 되기 때문에 매우 중요하다
이 방식으로 BERT Encoder는 범주를 예측하는데 도움을 주도록 contextualized embedding 하는것을 배운다
Self-Training
MCP task 이후 추가적인 훈련이 필요한 이유가 두가지 있다
MCP작업에서 보지 못한 label없는 문서가 아직 많이 있어(카테고리 키워드로 검출되지 않은것) 더 좋은 일반화를 위해 필요
masked 된 상태로 범주를 예측하는 훈련을 받았지만 모델이 전체 시퀸스를 볼수있는 [CLS] 토큰에는 적용되지 않았음
핵심 아이디어는 현재 예측$P$을 반복해 모델을 더 나아지게하는 타겟 분포 $Q$를 생성하고 이 두 분포간의 KL-divergnece 최소화 시키는 방향으로 학습
[CLS] 토큰에 위에 학습된 MCP를 적용하여 나온 값을 사용하여 target 분포를 업데이트
50개의 배치마다 5번수식을 통해 Q를 업데이트하고 4번식을 통해 모델을 학습한다
$Q$는 Hard 혹은 Soft label을 사용할수 있는데 실제로 soft label이 일관적으로 더 안정적인 결과를 제공하는것을 발견하였고 추가로 target 분포가 모든 객체에 대해 계산되고 threshold를 설정할 필요가 없다는 장점이 있음
4. Experiments
Datasets : 4가지 데이터셋을 사용
AG News
DBPedia
IMDB
Amazon
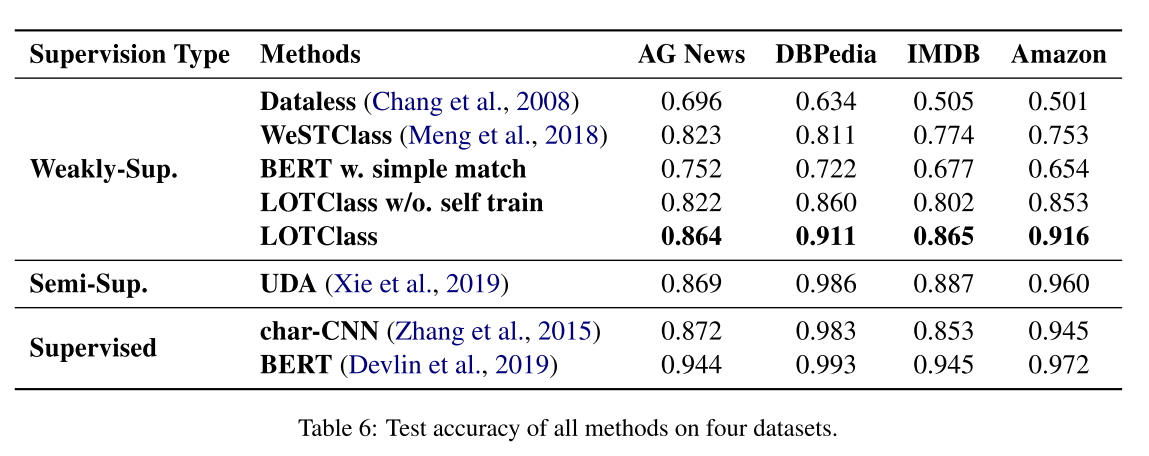
Compared Methods : 기존의 많은 방식들과 비교
supervised : 전체 데이터를 훈련에 사용
char-CNN : 그냥 character-level CNN (6층짜리 사용)
BERT : pre-trained 모델로 fine-tuning 실행
semi-supervised : 클래스당 10개의 레이블 문서, 나머지는 label 없이 사용
UDA (Unsupervised data augmentation) : 현재 SOTA 방식으로 back translation 과 TF-IDF 를 사용해 단어를 대체하여 augmentation을 수행하여 모델이 augmentation을 넘어 일관된 예측을 하게 만듬
weakly supervised : 모두 unlabeled 데이터 사용하고 평가시엔 test set 사용
Dataless : Label 이름과 문서를 Wikipedia 컨셉과 같은 의미공간에 맵핑하고 문서와 클래스간의 벡터 유사도를 기반으로 수행