<
Drop an Octave : Deducing Spatial Redundancy in Convolutional Neural networks with Octave Convolution
ALBERT : A Lite Bert For Self-Supervised Learning of Language Representations
ALBERT : A Lite Bert For Self-Supervised Learning of Language Representations
원논문 주소 : https://arxiv.org/abs/1909.11942
SQUAD 공식 홈페이지에 들렀다가 왠 처음보는 모델이 1위를 먹고 있기에
바로 찾아보니 일주일도 안된 따끈따끈한 논문!
요새 대부분 모델들이 커지는데 집중하는데 비해
버트의 파라미터 경량화와 성능향상을 함께 이루어낸 좋은 모델인듯 하다.
솔직히 버트 모델 좀 과하긴했지….
XLNet도 열심히 파려고 했는데 갈아탈 좋은 명분이 생겨서 구글님께 매우 감사.
게다가 수식이 거의 없어 보기좋….읍
Abstract
- 사전학습에서 모델을 키우는것은 대부분 성능에 좋은 영향을끼치나 학습속도나 메모리, 혹은 원인불명의 성능하락 같은 부작용도 있음
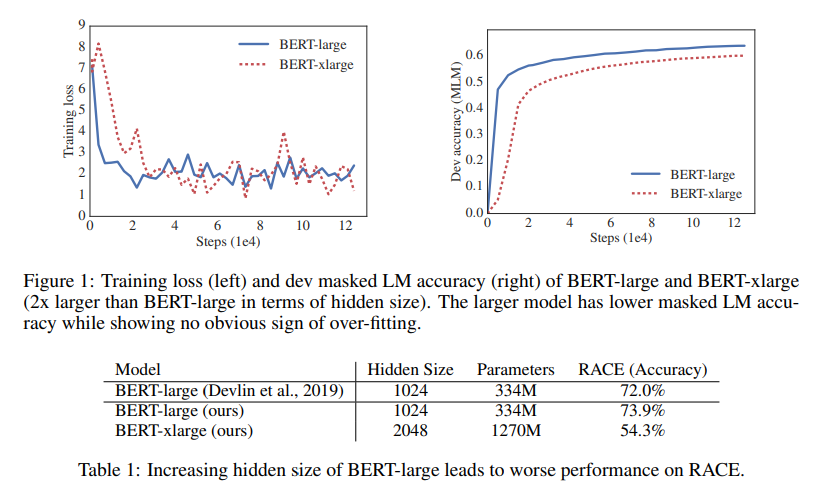
- 그림 1을보면 xlarge모델(hidden size 2배)과적합현상도 아닌듯 한데 성능이 더떨어지며, 표1을 보면 Bert-large 보다 RACE에서 확실히 성능이 하락하는 걸 보여준다
- 두가지 파라미터 감소테크닉을 사용하여 적은 메모리와 BERT학습의 속도를 향상시키고 성능마저 기존보다 좋아짐(배치사이즈가 커짐))
- 문장 일관성 평가를 위한 NSP 손실을 제거하고 새로운 손실을 사용
ALBERT 의 요소
- 기본구조
- Bert변형이니 당연히 Bert를 따라감 (GeLU를 사용한 transfomer Encoder)
- Facrorized embedding parameterization
- 기본적으로 $V$(어휘수)가 커야 작동이 잘되나 기존연구들은 $E$(임베딩) 은 $H$(히든사이즈)와 묶여있어서 $E$가 커지면 임베딩 매트릭스의 파라미터가 매우커지고 업데이트도 많이 되지않음
- $V \times H$ 를 레이어를 추가해 $V \times E + E \times H$ 로변경($H$ 가 $E$ 보다 크게 설정)
- Cross-Layer Parameter Sharing
- 파라미터를 효율적으로 사용하기위해 레이어단위의 파라미터 공유를 사용.
- FFN과 attention 부분 모두에 파라미터 공유를 사용
- 특정층의 입력과 출력 임베딩이 동일하게 유지되는 현상이 나타남, 임베딩이 수렴보단 진동하는것을 보임
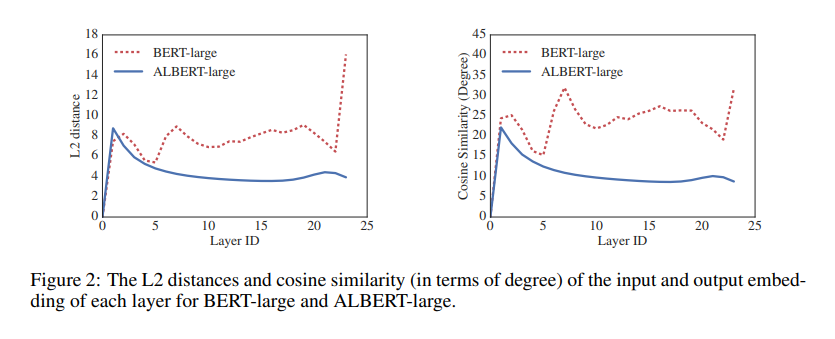
- Inter-sentence coherence loss
- NSP 손실을 제거(MLM에 비해 난이도가 너무쉬워 문제가 있다고 함)
- 대신 Sentence-Order Prediction 손실을 사용(SOP)

- 이 파라미터 감소가 ALBERT의 가장 중요한 부분이라함
- BERT 학습의 문제인 메모리 문제를 해결해줄 것으로 보임
- 임베딩 $E$는 전부 128로 통일(이유는 뒤에 나옴)
세부 실험 설정
- pre-training자료는 BookCoupus, 영어 위키를 사용 (약 16GB)
- 입력은 “[CLS] x1 [SEP] x2 [SEP]” 방식으로 사용(BERT의 NSP 입력방식)
- 입력 길이최대치는 512, 그리고 10%확률로 512보다 짧은 시퀸스를 무작위 생성
- Sentencepiece 를 사용한 3만개의 Vocab
- MLM을 위해 n-gram masking 을 사용하고 n은 확률적으로 결정하되 최대치는 3으로 결정, 확률은 아래와 같음
\(p(n) = \frac{1/n}{\sum^N_{k=1}1/k}\)
- 배치사이즈는 4096!!을 사용했고 lr=0.00176의 LAMB 옵티마이저를 사용.
- 기본적으로 125,000스텝 학습했고 CLOUD TPU V3을 사용 (모델에따라 64에서 1024개)
평가
- 임베딩 크기 변경에 따른 변화
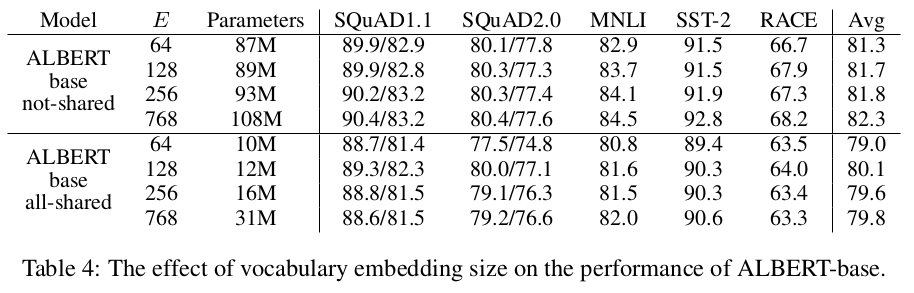
- 특이하게도 가중치 공유를 사용할시 128 위로 올릴시 성능이 거의 변화가 없어서 128을 사용 (언어임베딩은 128이면 충분한게 아닐까 함… 물론 내 예상)
- 파라미터 공유에 따른 변화
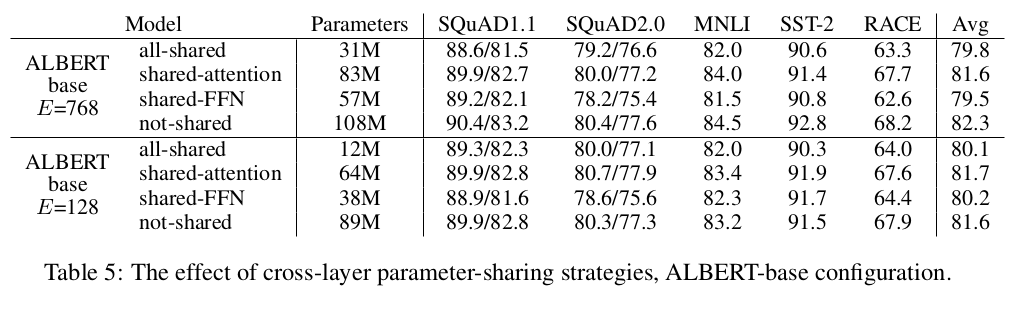
- FFN과 Attention 부분을 나눠서 공유하며 테스트
- 직관적으로 파라미터 공유는 전체적으로 성능이 떨어지지만 임베딩 128에서는 감소효과가 적어짐.
- Attention보단 FFN이 공유시 성능저하가 큼
- 학습방식에 따른 변화

- 아무것도 하지않은 XLNet과 Robert 방식, BERT의 NSP 방식, 그리고 ROBERT의 SOP 방식 비교
- Intrinsic 부분에서 MLM만 학습한것은 다른 방식에 영향을 못주고(해당 목적으로 학습을 아얘 안했으니..) NSP도 SOP에는 영향을 못주나 SOP의 경우 NSP에서도 효과가 있는것을 보여줌
- SOP가 문장 인코딩태스크의 성능에 더 좋은것으로 보임
- 네트워크 크기에 따른 변화
- ALBERT-lage의 설정을 사용하여 비교
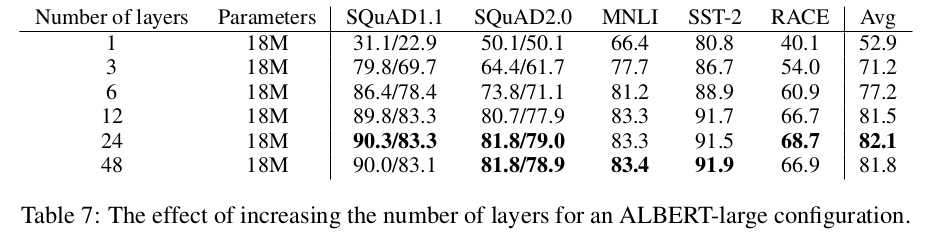
- 가중치 공유를 사용하므로 레이어가 늘어나도 파라미터의 변화가 없음
- 일반적으로 레이어를 늘릴떄마다 성능은 증가하나 학습속도가 느려짐
- 히든사이즈에 대한 비교
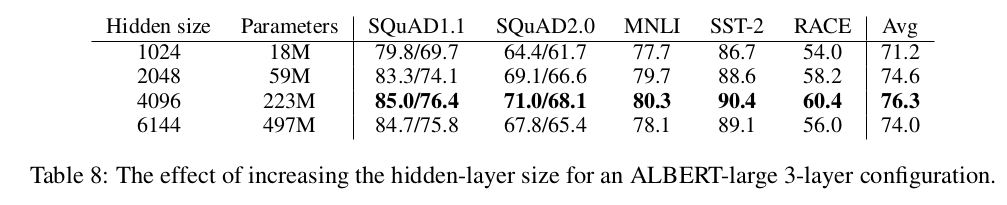
- 히든사이즈를 증가시키면 당연히 성능은 좋아지나 늘릴수록 효율은 안좋아짐
- 위 모든 모델은 과한 훈련을 했으나 과적합 되지 않고 수렴이 잘 되었다고 함
- 같은 학습시간 대비 성능

- ALBERT-xxlarge가 BERT-large보다 여러면에서 좋다는걸 보여주고 싶었는지 비슷한 시간을 학습한 결과도 첨부했고 물론 좋다. 안좋으면 안넣었겠지.
- 더 큰 네트워크에서의 레이어비교
- 4096의 히든사이즈를 가진 모델에서도 레이어를 24로 늘려봤으나 별 효과 없었다
- 레이어는 12면 충분하다고 결론냄. 여기도 표가 있지만 별의미없어 빼버렸…
- 추가데이터와 드롭아웃 제거
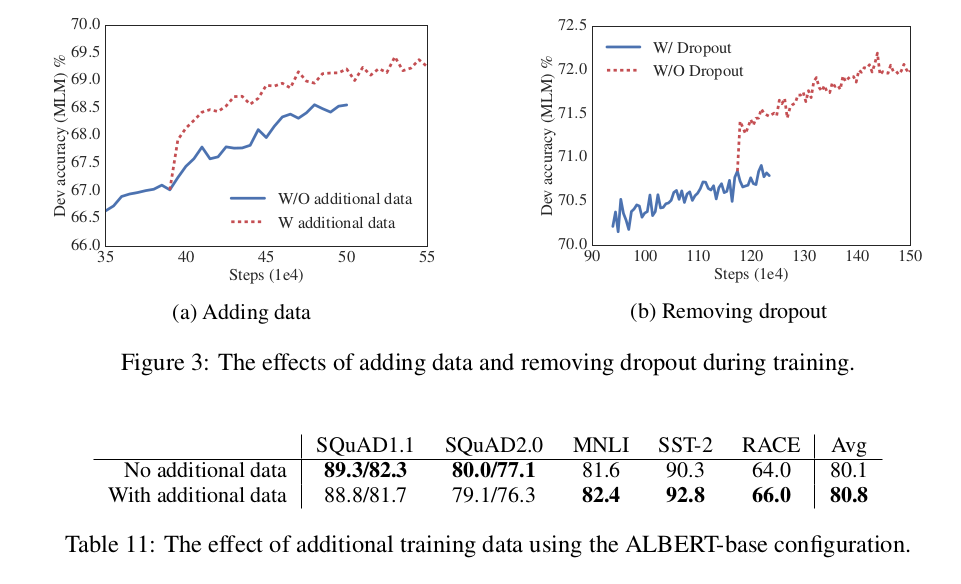

- 기존 사용된 데이터외에 XLNet과 RoBERT에서 사용된 추가데이터를 넣으니 학습시 성능이 급가속 되는것을 보이나 도메인 밖의 자료의 부정적 영향으로 인해 SQUAD에는 좋은 영향을 주지못하고 다른곳에서는 성능 향상을 보임.
- 그리고 100만번의 스텝 이후에도 과적합되지 않아 Dropout 을 제거했는데 상당한 성능향상을 보이고 전체적인 결과에 긍정적인 영향을끼침
- 이것은 CNN에서 Dropout과 BN을 함께 사용했을때 생기는 부정적인 영향이 Transfomer 기반에도 발생하는 것을 보여주는 최초의 예시임.
- 이제 제일 중요한 현재의 SOTA 와의 비교
- 최종모델은 ALBERT-xxlarge 를 사용하고, MLM과 SOP 손실사용, 그리고 Dropout을 제거하였다.
- 12 및 24층의 레이어를 사용한 여러 학습단계의 모델들의 예측평균을 사용
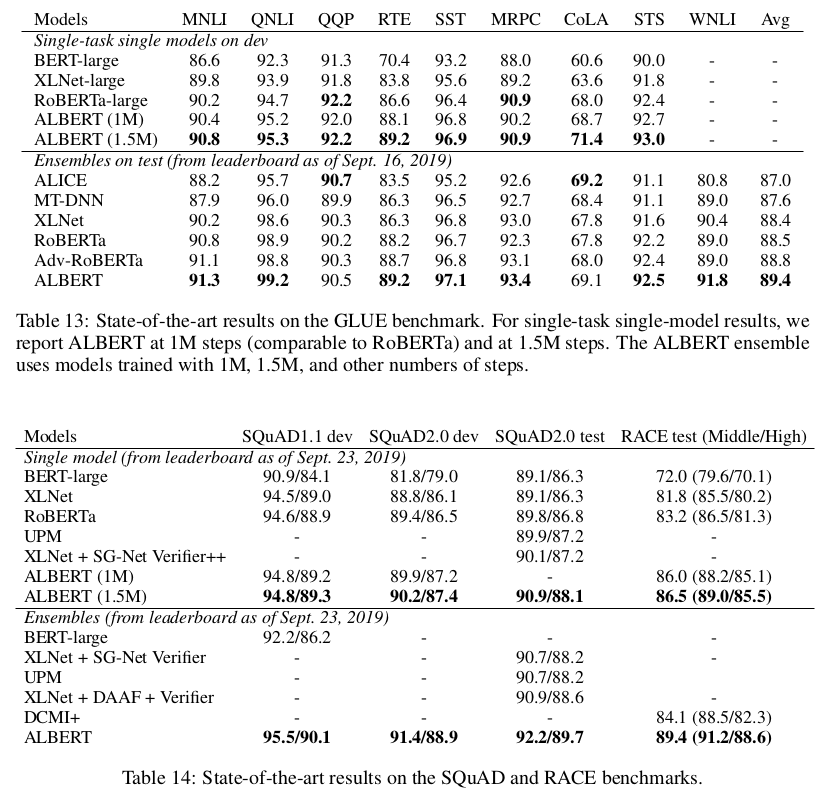
결론
- 파라미터는 매우감소하고 결과도 좋지만 구조가 작아진건 아니기에 계산이 매우 크니 보완할 방법이 필요하다.
- SOP도 아직 더 연구가 필요하다.