CartoonGAN : Generative Adversarial Networks for Photo Catoonization
CartoonGAN : Generative Adversarial Networks for Photo Catoonization
원논문 주소 : https://ieeexplore.ieee.org/document/8579084
OpenCV를 모바일에서 사용은 하게 만들었는데 이걸 어떻게 활용할까 고민중 보게된 논문이다
이 U-GAT-IT을 먼저 보긴 했었는데 대충봐서.. 다시볼겸 기초부터 다시보기로 했다.
참고로 조금 항마력이 필요하다
Abstract
- 간단히 설명하면 사진을 만화로 바꿔보자!
- 만화의 특성덕에 일반적인 손실로는 좋은 결과물이 나오지 못함
- 높은 수준의 추상성과 독특한 특성을 가짐
- 선명한 외곽선과 매끄럽고 단순한 질감
- VGG손실과 외곽선 보존을 위한 손실, 빠른 수렴을 위한 초기화 단계를 도입
Non-photorealistic rendering (NPR)
- 비현실적 렌더링 기법은 3D를 이용하는 등의 많은 연구가 있지만 알고리즘 기반으로 예술적인 부분을 표현하는 것은 매우 힘들다.
Stylization with neural networks
- 스타일 트랜스퍼 방식은 이미지와 유사한 스타일 이미지가 존재해야하고 해당 단일 스타일 이미지에 큰 영향을받는다
- 외곽선 및 음영 재현등 디테일 재현에 매우 약하다.
Image synthesis with GANs
- 가장 유망한 접근법으로 현재 많은 연구에서 사용하고있음
- Pixel to Pixel 방식으로는 페어링된 이미지 세트가 필요하다는 단점이 있음
- CycleGAN의 경우 이 문제는 해결이 되었지만 만화의 독특한 특성덕에 좋은 결과가 나타나지 않음 (원본정보를 자주 주입해 주는데서 생기는 문제인듯하다)
3. CartoonGAN
- 기본적으로 Pix2Pix의 구조를 따라감
- Residual Blocks 부분이 굉장히 성능이 좋다고 함
- 만화 이미지에 특성에 맞는 판별기를 설계
- $S_{data}(p)$ : 사진 데이터, $S_{data}(c)$ : 만화 데이터
3.1 CartoonGAN Architecture
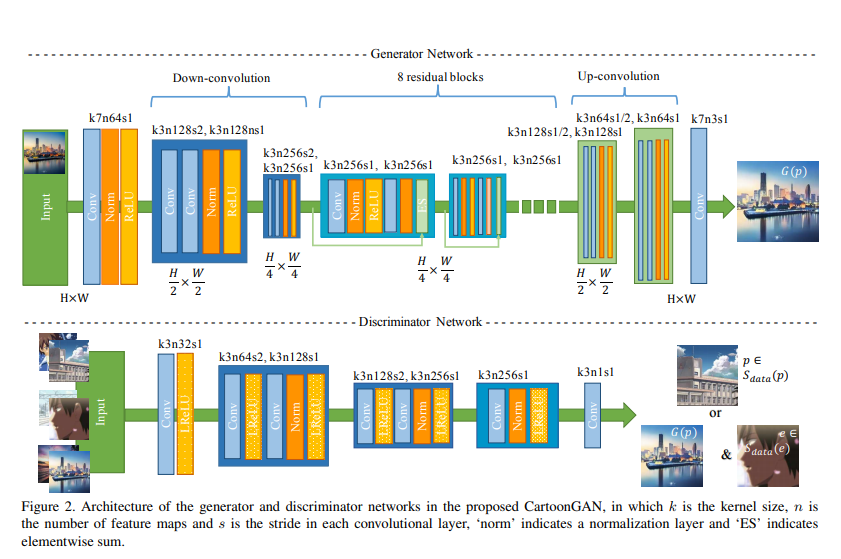
- Generator
- 변환모델이므로 일반 GAN과는 다르게 Input으로부터 결과를 생성
- 두번의 컨볼루션으로 인코딩 하여 매니폴드 변환에 필요한 피쳐를 추출하게 함
- 이후 8번의 Residual Block 을 거침
- 이후 스트라이드 1/2의 컨볼루션(Transposed)을 사용하여 업샘플
- 마지막으로 커널 7짜리의 컨볼루션 레이어를 사용하여 최종 이미지 생성
- Discriminator
- 입력된 이미지가 얼마나 만화같은지 구분하는 목적으로 학습
- 그러기에 전체적인 이미지보다는 국소적인 부분을 판단하도록 네트워크를 매우 얕게 설계
- 이후 두번의 stride가 들어간 컨볼루션으로 피쳐 사이즈를 줄이고 마지막에 간단한 블록 추가
- 특이하게도 Discriminator에서 LeakyRelu를 사용
3.2 Loss function
- $\mathcal{L}(G,D) = \mathcal{L_{adv}}(G,D) + w \mathcal{L_{con}}(G,D)$
- 기본적인 Adversarial Loss ($\mathcal{L_{adv}}$)에 추가로 $\omega$의 가중치를 가진 Content Loss ($\mathcal{L_{con}}$) 를 더해서 사용
- 여기서 $w$가 커지면 입력에서 더 많은 정보 유지해 되므로 더 디테일한 텍스쳐를 가지게 되고 낮아지면 스타일성이 강해짐
- 균형잡힌 값을 찾기위해 여러번의 테스트를 거쳐 10으로 설정
3.2.1 Adversarial Loss
\(\mathcal{L}_{adv}(G,D) =
\mathbb{E}_{c_i \sim S_{data(c)}[\log D(c_i)]} +
\mathbb{E}_{e_i \sim S_{data(e)}[\log (1-D(e_i))]} +
\mathbb{E}_{p_k \sim S_{data(p)}[\log (1-D(G(p_k)))]}\)
- 일반적인 GAN의 Adversarial loss로는 사진을 만화로 변환하기 충분하지 않다는 것을 발견
- 외곽선이 가장 중요한 특징이지만 전체 이미지에서 차지하는 부분이 넓지않기에 외곽선없이 명확한 쉐이딩을 가진 이미지를 판별시 혼란을 줄 수 있음
- 이를 피하기 위해 새로운 데이터셋을 생성
- $S_{data}(e)$ : 외곽선이 약해진 그림데이터
- 케니엣지검출, 영역확장, 가우시안 스무딩 3단계 적용

3.2.1 Content Loss
\(\mathcal{L}_{con}(G,D) = \mathbb{E}_{p_i\sim S_{data(p)}}[||VGG_l(G(p_i)) - VGG_l(p_i) ||_1]\)
- 만화 스타일을 유지하는 것도 중요하지만 입력과 결과의 내용이 중요한것도 매우 중요하다
- 사전훈련된 VGG에서 깊은층의 특정 레이어의 값을 가져오는 방식의 loss를 사용해 의미 보존
- 다른 모델들과는 다르게 특이하게도 L1 정규화를 사용( 여기서의 정규화가 조금이해가 안된다)
- 사진과 그림은 다른부분이 많아 변화에 대처가 잘되는 L1을 사용했다고 함
- 좋은 결과가 나오는데 있어 매우 중요한 부분이라고함
3.3. Initialization phase
- GAN은 비선형성이 매우 높아 기본적으로 무작위 초기화를 사용하기에 local minimum에 빠지기 매우 쉬워 이를 위한 초기화 단계를 제안
- Generator는 의미를 유지하면서 스타일을 재구성하는 것이므로 $\mathcal{L}_{con}$만을 이용해 재구성 학습을 먼저 시작.
- 이 간단한단계로 빠르게 수렴하는데 큰 도움을 주고 스타일 품질도 개선됨

4. Experiments
- Torch 와 Lua 를 사용하여 구현, 재현가능하도록 Titan Xp 사용

- paired 데이터가 필요 없으므로 쉽게 얻을수 있는 아티스트의 데이터만을 이용해 스타일 훈련이 가능
- 아티스트의 스타일을 효과적으로 학습 가능하다
4.1 Data
- 전부 256x256 사이즈로 크롭
- Fliker로부터 다운받은 6153장의 사진 중 5402 장을 학습에 이용, 나머지는 테스트
- 특정 아티스트의 만화 이미지 혹은 영화의 핵심 키프레임을 사용
- 만화 이미지 : 마코토신카이(4573), 호소다마모루(4212)
- 영화 : 미야자키하야오(3617), 파프리카(2302)
4.2 Comparison with state of the art

- NST와 비교
- (a)는 NST에서 입력과 비슷한 사진을 수동으로 선택하였고 한장으로는 그 스타일과 이미지가 다른때 제대로 학습을 못하는 것을 보임
- (b)는 확장하여 모든 이미지 사용해 다양한 스타일은 학습가능하나 일관성없는 결과가 나옴
- CycleGAN과 비교(identity loss 미적용 및 적용)
- (d)는 미적용 결과고 원본내용을 거의 유지하지 못함
- (e)는 위 문제는 해결했으나 여전히 좋은 결과는 보이지 못함

- CartoonGAN
- 아티스트의 특성을 잘 반영한 결과가 나오며 특히 가장 중요한 외곽선이 잘보임
- CycleGAN의 경우 에폭당 2291.77s, 3020.31s 소요되나 CartoonGAN은 1517.69s 소요
- CycleGAN은 역매핑까지 포함해 두가지 모델을 학습해야 해서 오래걸림
- 사이클 구조가 아닌 VGG 피쳐맵을 이용해 훨씬 효과적으로 학습

- CNNMRF 와 Deep Analogy 와의 비교
- 이미지는 수동선택(image1)과 랜덤선택(image2) 사용
- 둘다 만화스타일은 재현하지못함 (근데 원샷으로 스타일재현이 어려운건 당연한듯 하다)
4.3 Roles of components in loss function

- 초기화 단계는 확실히 빠르게 수렴하는 것에 도움을 줌
- VGG loss 를 사용하더라도 사진과 만화의 큰 스타일 차이 때문에 Edge loss 가 필요
- 특히 l1 를 사용했을때가 특성이 더 살아나는것이 보임(c와 e 비교)
5. Conclusion and Future
- 만화 스타일 재현을 위해 엣지 손실, l1정규화 등을 사용하여 좋은 결과물을 만들었다
- 앞으로는 만화에서 중요한 얼굴의 개선을 위해 얼굴의 피쳐들을 어떻게 활용할 것인가 연구 할 것이라 한다.
- 새로운 손실도 더 연구 예정이라 함
