아… 또 BiGAN이 아키텍쳐를 SAGAN을 사용하는바람에.. 하나더 보게되었… 이건 중요한 부분만 번역해서 정리했다. 이것도 다른 아키텍쳐를 가져오지만 다행히 DCGAN이라 바로 구현가능할듯.
이 논문은 이미지 생성을 위한 장거리 의존성 모델링인 어텐션을 사용한 SAGAN을 제안한다. 기존의 컨볼루션 GAN들은 저해상도 피쳐맵의 특정 공간만을 사용하는 함수를 이용하여 고해상도 디테일 을 생성한다. SAGAN에서는 디테일들이 모든 피쳐 위치에서 나오는 신호로부터 생성될수 있다. 게다가 discriminator는 이미지의 먼 부분의 세부적인 디테일들이 얼마나 일치하는지 확인할 수 있다. 더 나가 최근 연구는 Generator의 상태가 GAN의 퍼포먼스에 영향을 끼치는것을 보여준다. 이 것을 활용해, GAN의 Generator에 Spertral normalization 을 적용하고, 이것의 효과를 동적으로 훈련하며 찾았다. 제안된 SAGAN은 기존의 작업들보다 좋았는데, ImageNet 데이터셋에서 공인된 최고의 IS를 36.8에서 52.52로 올리고, FID를 27.62에서 18.65로 감소시켰다. 어텐션 레이어의 시각화는 Generator가 고정된 모양의 지역 보다는 물체 모양에 해당하는 지역을 활용하는 것을 보여준다.
여긴 패스!

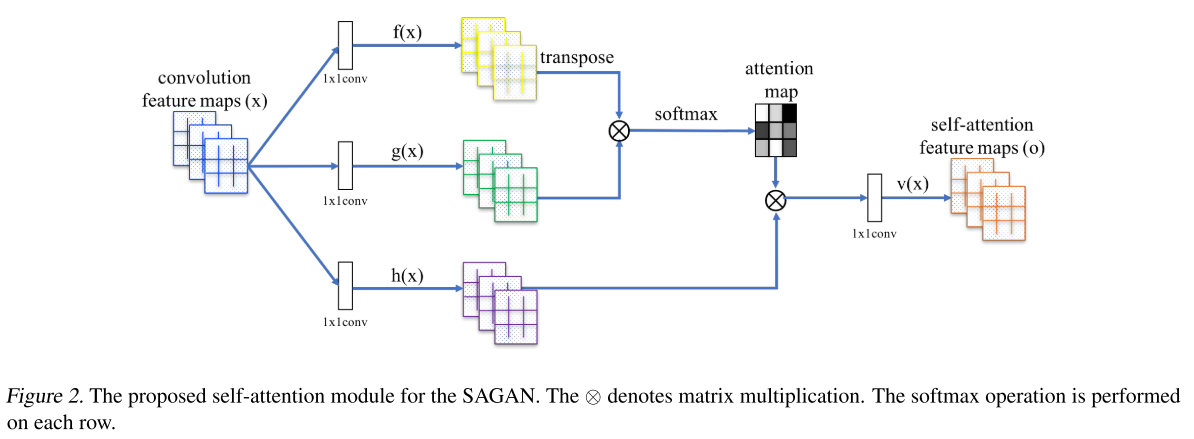
이미지 생성을 위한 대부분 간 작업 은 컨볼루션 레이어를 사용하여 구성된다. 컨볼루션 과정은 국지적인 정보를 계산하고, 그래서 컨볼루션 레이어만을 사용하는것은 이미지가 가진 장거리 의존성을 표현하는 모델링에는 비효율적이다. 이 섹션에서 non-local 모델을 적용한 셀프어텐션을 사용한 GAN 프레임워크를 소개한다. Generator와 Discriminator에 둘다 적용하여 멀리떨어진 공간 사이의 관계를 효과적으로 모델링한다. 우린 이 방법을 Self-Attention Generative Adversarial Networks 라 부르는데 셀프 어텐션 모듈이 있어서이다.
앞의 히든레이어 $x \in \mathbb{R}^{C \times N}$ 에서 가져온 이미지 피쳐들은 어텐션을 위해 피쳐공간 $f,g$ 로 변환되고, $f(x)=W_fx, g(x)=W_gx$ 일 때
\[\beta_{j,i} = \frac{\exp(s_{ij})}{\sum^N_{i=1}\exp(s_{ij})}, \mathrm{where}\ \ s_{ij} = f(x_i)^Tg(x_j),\]와 $\beta_{j,i}$ 는 $j$번째 위치를 합성할때 모델이 $i^{th}$ 위치에 집중하도록 모델을 확장하는것을 표시한다. 여기서 $C$ 는 채널의수, $N$은 전단계 은닉층에서 나온 피쳐들의 위치의 숫자이다($i \times j$). 어텐션 레이어의 출력은 $o=(o_1,o_2,\cdots,o_j,\cdots,o_N) \in \mathbb{R}^{C \times N}$, 이때
\[o_j = v(\sum^N_{i=1}\beta_{j,i}h(x_i)), h(x_i) = W_hx_i, v(x_i) = W_vx_i\]$W_g\in\mathbb{R}^{\bar{C}\times C}$, $W_f\in\mathbb{R}^{\bar{C}\times C}$, $W_h\in\mathbb{R}^{\bar{C}\times C}$, $W_v\in\mathbb{R}^{C\times \bar{C}}$ 이 가중치 행렬로부터 학습되고, 1x1 컨볼루션으로 구현된다. 채널숫자 $\bar{c}$를 $C/_k$ 로 감소시켜도 어떤 현저한 퍼포먼스 하락도 발견하지 못했다(이미지넷 $k = 1,2,4,8$로 작은 학습 결과). 메모리 효율을 위해 우리는 $k=8$로 결정하엿다.
추가적으로 어텐션레이어의 출력에 상수 파라미터를 곱하고 입력 피쳐맵을 더했다. 이 최종 출력은 아래와 같다
\(y_i = \gamma o_i + x_i\)
여기서 $\gamma$는 학습가능한 상수고 0으로 초기화된다. 이 변수를 소개하자면 처음엔 지역적 정보에 의존하도록 하고, 점차적으로 위치적 정보의 가중치를 늘려간다. 이렇게 한 이유는 매우 직관적인데, 쉽게 작업을 배운 후 점점 복잡도를 올리고 싶기 때문이다. SAGAN에서 생성기와 판별기 양쪽에 적용하는 어텐션 모듈을 제안한다. 인기있는 방법인 적대적 손실의 힌지버전을 최소화하여 모델을 학습한다.
우리는 또한 GAN의 안정화를 위해 두가지 테크닉을 조사했다. 첫번째는 spectral normalization 를 생성기와 판별기에 넣엇다. 두번쨰로 two-timescale update rule (TTUR)을 적용했는데 효과적이었고, 우리는 특별히 정규화된 판별기의 느린 학습을 다루는데 그것을 사용한다.
(Miyato et al., 2018)에서 GAN의 학습을 안정화 시키기위해 Spectral normalization을 판별기에 적용하는것을 제안했다. 판별기의 각 레이어의 spectral norm(최대 특이값)을 제한하는 립쉬츠 상수를 제한한다. 다른 정규화 기법과 비교하면 파라미터 튜닝이 필요하지 않고(모든 레이어에 대해 1을 적용해도 잘 작동한다), 연산 비용또한 상대적으로 작다.
생성기의 상태는 GAN의 성능에 중요한 원인이 된다는것을 기반으로 생성기에도 이 이점을 받을수 있는것에 대해 의논했다. Spectral normalization은 unusal 경사를 피하고 파라미터 규모의 확대를 방지한다. 우리는 경험적으로 양쪽에 넣는것이 생성기의 업데이트당 판별기의 학습수를 줄이는것을 가능하게 하고, 훈련 계산비용을 현저히 줄여줬다. 훈련간의 안정성이 증가하는것도 보여줬다.
기존의 작업에서, 판별기의 정규화는 종종 GAN 학습을 느리게했다. 실제로 일반적인 정규화된 판별기들은 생성기 학습당 다수의 학습이 필요했다. (Heusel et al.,2017)은 학습기와 판별기의 학습율의 분리를 사용하는것을 지지했다(TTUR). 정규화된 판별기가 학습하는것이 느려지는 문제에 대해 보상하고 적은 판별기 스텝을 가능하게 했기에 이것의 사용을 제안했고 이방법을 사용하여 같은 시간에 더 좋은 결과를 가능하게했다.
이 방법을 평가하기위해 LSVRC2012 이미지넷 데이터셋을 사용했다. 우선 두가지 안정화 테크닉의 실험결과를 5.1에서 보여줬다. 그리고 셀프어텐션 에 대하여 5.2에 나오고, 5.3에선 SAGAN과 이미지 생성의 SOTA 모델과 비교하였다. 모델은 4개의 GPU를 사용하여 약 2주간 학습하였고, sychronous SGD를 사용하였다.
양적 평가를 위해 인셉션 스코어와(IS) FID를 사용하였다. 다른 대안도 존재하지만 널리 사용되지는 않는다. IS는 분포의 KL 발산을 계산한다. 높은 IS는 좋은 이미지 퀄리티를 의미한다. 이것을 사용한 이유는 널리 사용되기도 하고, 기존의 작업들과의 비교가 가능하기 때문이다. 하지만 IS의 심각한 한계에 대해 이해하는것은 중요하다. 모델은 특정 클래스를 확신하는 샘플을 생성을 보장하는것을 주로 의도하고, 모델이 많은 클래스를 생성하면 디테일의 사실성이나 해당 클래스내에서의 다양성을 확실하게 평가하진 못한다. FID는 좀더 원칙이 있고 종합적인 측도인데, 이것은 생성된 샘플의 다양성과 사실성을 더 고려하는 것을 보여준다. FID 는 리얼 이미지와 생성된 이미지의 Wasserstein-2 거리를 계산하는데, 피쳐공간을 구하는데는 Inception-v3를 사용한다. 전체 데이터 분포에 걸쳐 계산하는 FID 외에, 생성된 이미지와 각 클래스의 데이터셋의 이미지들과의 거리또한 계산한다(intra FID라 부른다). 적은 FID와 intraFID는 합성과 실제 분포 사이의 거리를 가깝게하는것을 의미한다. 모든 우리 실험에서 계산을 위해 각 모델에서 랜덤하게 생성된 50k개의 샘플을 랜덤하게 생성 하였다
모든 SAGAN 모델은 128해상도 이미지 생성을 했다. default는 spectral normalization을 양쪽에 사용하였고, SAGAN 은 conditional batch normalization을 생성기, 판별기안에 투영에 사용하였다. 모든 모델에서 Adam($\beta_1=0,\ \beta_2=0.9$) 을 사용했고 학습율은 판별기 0.0004, 학습기 0.0001을 사용했다.
이 섹션은, 제안된 안정화 기법인 SN과 TTUR의 효과에 대해 평가하기 위해 실행한 실험들이다. Figure 3에 있고, base model은 현재 SOTA인 SNGAN 사용하여 비교하였다. 베이스모델에서 SN은 discriminator 에만 적용되어있다. 기본 모델의 경우 매우 불안정한것을 보여준다. 학습 초기에 mode collapse가 보인다. SNGAN 원본 논문에 따르면 이 현상은 D와 G 에 5:1의 비균형 업데이트를 사용하면 매우 완화된다고 하는데, 모델의 집중화 속도를 위해서는 1:1로 안정적으로 훈련하는게 중요하다. 그래서 우리가 제안한 기법을 사용하면 동일한 시간에 더 나은 결과가 나오는 것을 의미한다. 따라서 G와 D 의 업데이트 비율을 찾을 필요가 없다. 그리고 Figure3에서 보여지듯 양쪽에 SN을 넣는것은 1:1 업데이트에서도 매우 안정화된다. 그러나 퀄리티가 학습중 단조롭게 증가하진 않는다. 260k번째 에선 FID와 IS가 떨어지기 시작한다. 여기에 비균현 학습율을 적용하자 학습기간 내내 단조롭게 증가하는것을 보였다. 총 100만번의 스텝동안에도 샘플의 품질 및 FID, IS 의 저하는 발견하지 못했다. 이 두 결과는 제안된 안정화 기법의 효과를 입증하거나 적어도 그 부분적으로 효과가 있다는 것을 증명한다. 나머지 실험에서 모든 모델은 양쪽에 SN과 TTUR을 사용하여 1:1 업데이트를 시행한다.
Self-attention의 효과를 보기 위해, 다르른 레이어에 적용된 몇개의 SAGAN 모델을 만들었다. Table1에서는 고수준 피쳐맵에 적용하는것이 저수준 피쳐맵에 적용하는것보다 좋은 성능이 나오는 것을 보여준다. 그 이유는 더 큰 피쳐맵에서 더 많은 선택의 자유를 얻기 때문이다, 그래서 작은 피쳐맵에 적용할떈 그냥 지역적 모델링과 비슷하다. 이것은 어텐션이 G와 D 모두에 장거리 의존성을 직접 모델링하는 힘을 주는것을 증명한다. 추가적으로 베이스모델과 우리의 SAGAN를 비교하면 더 좋은 효과가 나오는것을 보여준다.
Residual Block과 비교하면 같은 파라미터에서 어텐션이 더 좋은 결과를 보여준다. 8x8 피쳐맵에서 Residual Block으로 교체시 불안정해지고, 퍼포먼스를 현저히 떨어트린다. 다른 훈련이 잘 되는 경우에도 점수면에서 여전히 나쁜 결과가 나온다. 이 비교는 SAGAN으로 인한 향상이 단순히 모델의 규모 때문은 아니라는 것을 보여준다.
생성시 학습된 내용을 더 잘 보기위해 SAGAN의 Generator의 어텐션 가중치를 시각화했고 Figure1과5에 나와있다
SOTA 모델인 ACGAN, SNGAN 과의 ImageNet 조건부 이미지 생성 비교도 했다. Table2에서 보여지는데 IS, intra FID, FID 모두에서 최고의 점수를 달성했다. IS는 36.8에서 52.52로 현저히 높은 향상을 보여줬다. 또한 낮은 FID는 어텐션 모듈이 이미지 지역 사이의 장거리 의존을 모델링함으로 원래 이미지의 분포를 더 잘근사하게 만들었다는것을 보여준다.
Figure6은 ImageNet의 클래스의 생성된 결과를 보여준다. 물고기나 새 등의 복잡한 구조나 패턴이 있는 것에선 SAGAN이 더 좋은 퍼포먼스를 달성한 것을 관찰할수 있으나 벽이나 계곡, 코랄버섯같은 것에서는 좋은 성능이 나오지 않았다. 그 이유는 SAGAN은 일관적으로 발생하는 장거리, 혹은 전역수준의 의존성을 계산하는데 단순한 질감을 위한 모델링에선 지역모델링과 유사하기 때문이다.
이 논문에서 Self-attention을 포함한 SAGAN을 제안했고, 이 모듈은 장거리 의존성을 효과적으로 모델링한다. 추가적으로 SN과 TTUR로 학습 속도와 안전성을 향상시켰고 ImageNet의 조건부 생성에서 SOTA를 달성했다.
